Highlights from 15 years of Croatian Web Archive (HAW)
The National and University Library in Zagreb in 2019 celebrates 15th anniversary of the Croatian Web Archive
The Croatian Web Archive (HAW) established its full service in 2004. The system for archiving was built in collaboration with the University of Zagreb University Computing Centre (Srce). The basis for the start of web archiving in Croatia was the Library Law from 1997 that enabled the NSK to collect, process and preserve online publications. In February 2019, the new Law on Libraries and Library Activities was enacted that provided the necessary improvements for the web archiving in Croatia.
First approach – selective archiving
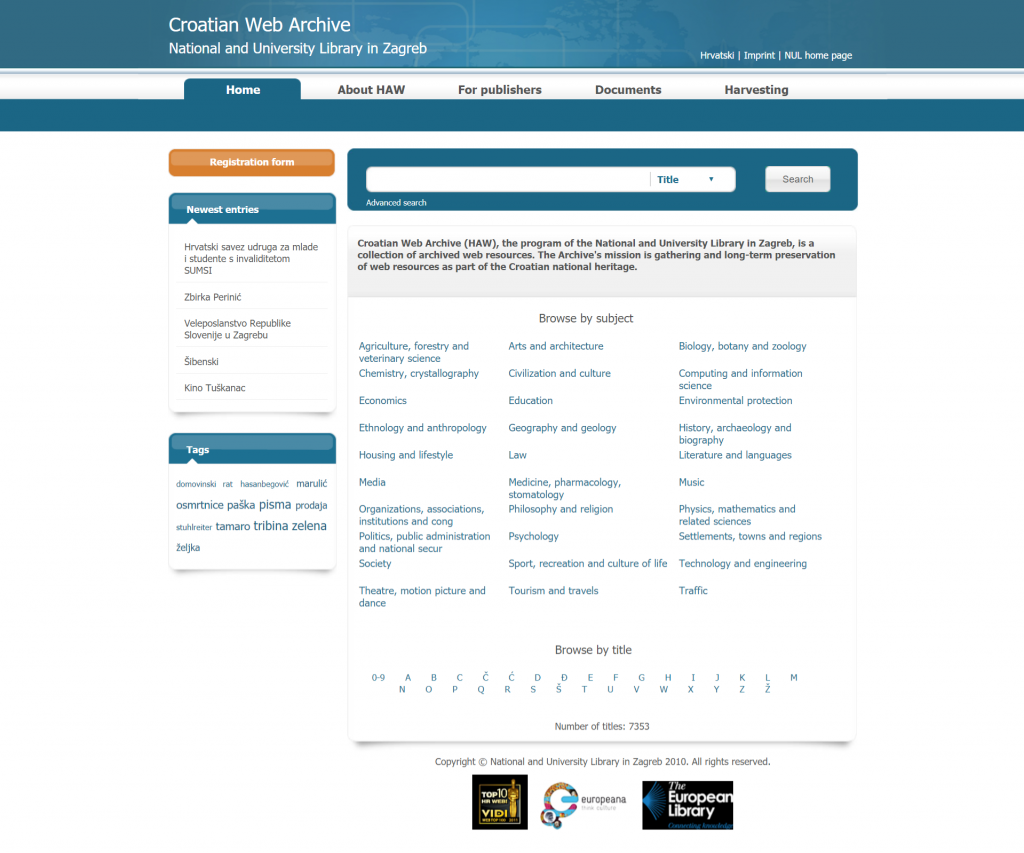
The NSK started to archive online resources selectively by establishing the selection criteria for cataloguing and archiving of web resources. Each resource has a full level of bibliographic description and is retrievable in the online catalogue as well as through the Croatian Web Archive website. Until today, there are more than 7400 archived resources.
From identification to archived copy (workflow)
The online resources are identified using several methods. The legal obligation of the website owners, publishers and/or content providers is registration of the online resources – which they can do by filling the Registration form. Nevertheless, the majority of resources are identified through manual searching and browsing the web.
Once catalogued, resources are daily transferred to the custom-made archiving system, where the archiving process starts.
Quality control of archive copy
Great care is taken to ensure the quality of each copy and it is assessed individually – a web curator (librarian) manually sets parameters, which ultimately result in the highest quality of archived copies. The special emphasis is given to news media, which are archived daily.
Searching, browsing and citations
The resources on the HAW portal can be searched by any word in the title, URL or keywords. For the detailed search the advanced search is also available. Users can browse the HAW alphabetically and through subject categories, which are extracted from the UDC field in the Library catalogue.
Since 2018, the persistent identifiers – URN: NBNs are assigned to all archived titles and instances, enabling a reliable source for citations.
Example: Večernji.hr (urn.nsk.hr/urn:nbn:hr:230:620090)
The metadata from HAW is also available on the Europeana portal, making it the only web archive searchable via Europeana.
TLD harvestings and thematic collections
The annual harvesting of the national domain .hr started in 2011 and is conducted with an open source crawler Heritrix, adjusted by Srce. Last harvesting from 2018 was carried out by Heritrix 3.0. A seed list of URLs of all active .hr domains is provided by Croatian DNS service in CARNet. Each harvesting requires some adjustment: the limitation of depth, the maximum number of resources, the maximum file size, the depth of embedded resources and robot.txt rules.
Since 2011 the Croatian Web Archive periodically harvests websites related to topics and events of national importance like important national and political events, occurrences whose materials tend to disappear quickly from the web as well as unexpected situations in the world of politics, natural disasters etc. Thematic harvesting is also carried out with crawler Heritrix and so far, ten thematic harvestings have been conducted.
TLD harvestings and thematic collections are publicly available via HAW’s website through the OpenWayback access interface.

The development plans of HAW include:
- the launch of the new web interface with new functionalities and features
- full-text search for the domain harvests
- news sections for web archiving community and researchers
- metadata integration in digital library system.
In the year when HAW celebrates its 15th anniversary, NSK is very proud to be the host of the 2019 IIPC General Assembly and Web Archiving Conference. We are looking forward to sharing and exchanging ideas and experiences, meeting you and welcoming you in Zagreb!
Downolad HAW flyer here.