
Link Analysis
As large bodies of websites are captured, so are the links and connections between them. These networks of linked sites and data can be mined to observe the relationships between individuals, organizations, and ideas over time. Just as this kind of analysis is done on websites and social networks on the live Web, it can be used with web archive datasets to view changes over time or at points in the past.
Examples:
Babel 2012 Web Language Connections, Hannes Mühleisen (CWI): Project using Common Crawl – captured websites to discover and visualize links between websites in different languages.
Study of ~1.3 Billion URLs: ~22% of Web Pages Reference Facebook, Matthew Berk (Zyxt Labs, Inc.): Analysis of Common Crawl – captured website linkages to Facebook
Outreach and Education
Because the web is such a dynamic and visible part of human culture in the 21st century, it has naturally become an integral part of the services offered by educational and cultural heritage institutions. In a few instances, web archives have been used in physical museum exhibits and as components of online exhibits; there are also efforts to involve schoolchildren in the creation of web archive collections in order to engage them with history and highlight the importance of capturing this valuable resource.
Links:
K-12 Web Archiving (Archive-It & Library of Congress): Initiative in which 10 K-12 schools use Archive-It to select and capture web content for archiving.
Accountability
Crawling websites over time allows for modifications to content to be observed and analyzed. This type of access can be useful in ensuring accountability and visibility for web content that no longer exists. On one hand, companies may archive their web content as part of records management practices or as a defense against legal action; on the other, public web archives can show changes in governmental, organizational, or individual policy or practices.
Examples:
Why Social Media Archiving Reduces Regulatory Risk, Mark Middleton (Hanzo Archives): Blog post describing the benefits of web archives in terms of accountability and authenticity, by providing “proof of authenticity” and “clear audit trails” for web content.
Policy for Responding to Legal Requests (Internet Archive)
Legal FAQ (Internet Archive): Internet Archive policy on authenticating web content found in the archive.
This case study is part of a Web Archiving Use Cases report written by Emily Reynolds for the Library of Congress.
Persistent Linking

Image attributed to www.futureatlas.com
Because websites and other digital content can disappear or change without warning, web archives offer the opportunity for users to provide links to specific, stable versions of the content in question. This may be achieved either with formal persistent identifiers assigned to each resource, or by means of a consistent and stable URL structure for accessing resources. Having access to a known version of a website at a specific location allows for users to reference this content and access it knowing precisely which version of the website is being used.
Examples:
Resources in the Library of Congress Web Archive are assigned a unique Citation ID, which redirects to the location of the archived website. These IDs ensure that even if the archive’s standard URL structure should change, cited websites will still be able to be located.
How do I cite Wayback Machine URLs in MLA format? (Internet Archive)
The Internet Archive gives specific information about how best to cite archived websites in publication, based on the MLA citation standard.
This case study is part of a Web Archiving Use Cases report written by Emily Reynolds for the Library of Congress.

Social media from 2011 Egyptian revolution, showing broken image links
Historic Preservation
As more news reporting shifts onto rapidly-updating, informal social media feeds, a great deal of data relating to current events stands to be lost. Web archives provide access to this short-lived content, ensuring that these parts of the historical record will not be lost.
Examples:

Access to Deleted or Modified Content
Web archives can provide access to sites that have since been deleted or changed, so that users can specifically access material that they are no longer able to access on the live web. This is perhaps the use of web archives most familiar to casual users, as the Internet Archive’s Wayback Machine and similar services make the contents of web archives easily accessible based on URL and date.
Examples:
Text Mining
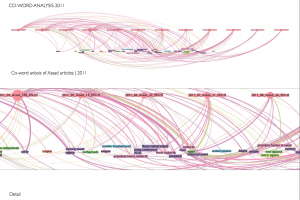
Large‐scale corpuses of captured websites offer the possibility for analysis of textual patterns and trends. Research projects studying the frequency of term usage or sentiment analysis have used web archive collections to extract, visualize, and analyze the language used in crawled websites.
This type of analysis can uncover relationships such as co‐occurrence frequency between terms. Sentiment analysis can also be performed on large bodies of text to determine the emotions used when discussing specific topics. Much like digitized books can be mined for language usage patterns, websites show modern patterns of language.
Examples:
“The Ngram search is a phraseusage visualization tool which charts the monthly occurrence of userdefined search terms or phrases over time, as found in the UK Web Archive.”
Searching the (News) Archives, Web Archive Retrieval Tools (University of Amsterdam) (findings 1 and 2)
Demonstration of the possibilities of research with web archive search tools, focusing on a collection of a Dutch news aggregation website. Shows word frequency visualizations and analysis of term cooccurrence over time in relation to major news events.
Sentiment Analysis and the Reception of the Liverpool Poets, Helen Taylor (Royal Holloway)
Proposal for using web archive collections to analyze online discussion of 1960s Liverpool poets, in comparison to data from newspapers and other formally published reviews.
Footprint of the world top companies, Alexandre Marah and Ferenc Szabó (University of Tewnte)
Project using Common Crawl – captured websites to count mentions of the top 1000 companies on Forbes’ list of The World’s Biggest Public Companies
Analysis of Technology Trends

The formats captured in web archive collections can serve as a timeline for the development of web technologies. Analysis on captured websites can show changes in usage of file formats, programming languages, markup, and other attributes over time. These datasets show the rise and fall of various web formats, perhaps highlighting formats that need preservation attention or showing trends in markup and formatting.
Examples:
“The dataset is a format profile, summarising the data formats (MIME types) contained within all of the HTTP 200 OK responses in the JISC UK Web Domain Dataset (19962010).”
Web Data Commons, Christian BTechnology)Christian Bizer et al. (University of Mannheim & Karlsruhe Institute of Technology: “More and more websites have started to embed structured data describing products, people, organizations, places, events into their HTML pages using markup standards such as RDFa, Microdata and Microformats. The Web Data Commons project extracts this data from several billion web pages. The project provides the extracted data for download and publishes statistics about the deployment of the different formats.”
An analysis of the use of JavaScript libraries on the web, Dennis Pallett et al. (University of Twente): Project using CommonCrawl captured websites to discern and analyze the most common JavaScript files and libraries in use on the most common JavaScript files and libraries in use on the web.